Loading...
Sentiment Analysis via Scraped Tweets.
We chose Sentiment Analysis because of two reasons.
covid-19 and flight. That's already our topics!covid-19 when travel through air. Perhaps sentiment analysis won't tell exactly how but that's the way on it.To be more specific, why we want to find sentiment of tweets? First, we want to know how people feel when they are traveling by plane under the pandemic of Covid-19, that is, does people feel positive more or negative more under such circumstances. Second, we want to know the sentiment through out the timelines. When does people feel negative more?
We use vaderSentiment package to do grading. This is a great package based on lexicon method. It does not only contains emotional vocabulary, but also has a lot emoji and emoticon. We use it to calculate the sentiment for each tweet.
The result for this part is also too large to upload. It extract the content in result_covid_flight_cleaning.csv (which is also generated in Tweets cleaning section) and generate results in a new csv file named result_covid_flight_cleaning_sentiment.csv.
For more details please check it in our code file TweetsSentiment.py
For this part we manually add tags by determining the sentiment for a tweets. It included 2 parts here.
First we need to sample a few tweets. Here we extracted 50 tweets randomly from result_covid_flight_cleaning.csv. And we manually labeled each of these 50 tweets. Sometimes it's really hard to determine it is positive, negative or neutral even for human beings like us. We wrote a small script named TweetsTagging.py for this task and it will generate a tagged file named result_covid_flight_cleaning_tag.csv (and it is uploaded on github).
Second we want to compare it to the sentiment grading done by vaderSentiment. In the code TweetsSentimentAccuracy.py, we calculated the sentiment of each tweet and compared it with our manually labels. It will generate the result in a file named TweetsSentimentAccuracyResult.txt.

For this part we want to analyze some result by grading sentiment for each tweets. We summarized the total amount of tweets in each month by their sentiment. The result (TweetsSentimentAnalysisResult.txt) is generated by code file named TweetsSentimentAnalysis.pyand it looks like this:
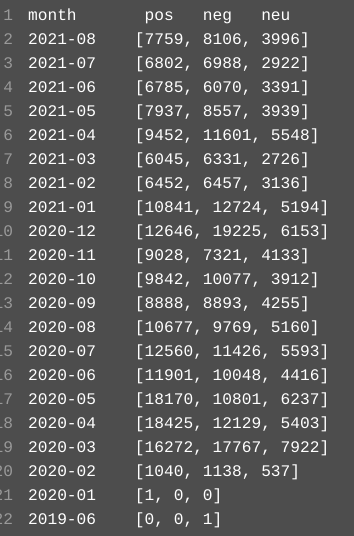
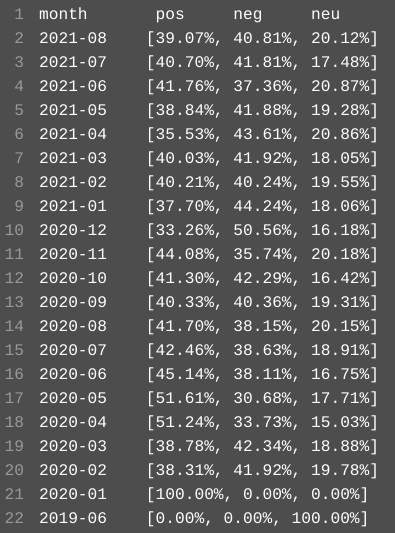
Judging by the result we may conclude that: